Resolving Incidents and Service Requests via Swarming Method – does it work?
Share:
Date:
October 2020

key fact
The Level 1, 2 and 3 support model has been the go-to standard for the last 20+ years, providing a structured method for resolving Incidents and fulfilling Service Requests. Is it time for a rethink?
On the assumption you do not have a personal hotline to “Mr/Ms/Mx Dependable” in IT who always resolves your IT issues (potentially ahead of higher priority work), you are likely to be raising Incidents and Service Requests via your online Service Portal or by calling your Service Desk.
This first point of human interaction is known as ‘Level 1’ support. Resolution at this stage provides a better service to the customer, and at a low cost, not only due to minimal effort involved of one person working on your Incident/Request, but also due to the lower cost of a Service Desk Advisor (albeit there’s plenty of debate that these superhumans should be your best paid colleagues!). Each interaction with the Service Desk equates to an average of £15.
(See the “IT Key Metrics Data 2020: Infrastructure Measures — IT Service Desk Analysis” from Gartner for further details.)

If the Service Desk Advisor is unable to complete the task, be that due to capability, proximity or access constraints, the ticket is typically sent to a more experienced / onsite / secure second line team. Interactions at this ‘Level 2’ stage cost more than using the Service Desk due to the higher skill level involved.
If the Level 2 team are unable to complete the task, the developer team or vendor (where appropriate) is engaged. Interactions at this ‘Level 3’ stage are more expensive than Level 2 (you may not be paying a per instance charge with your vendors, but you will still be paying for it via your annual support agreement).
See summary model below
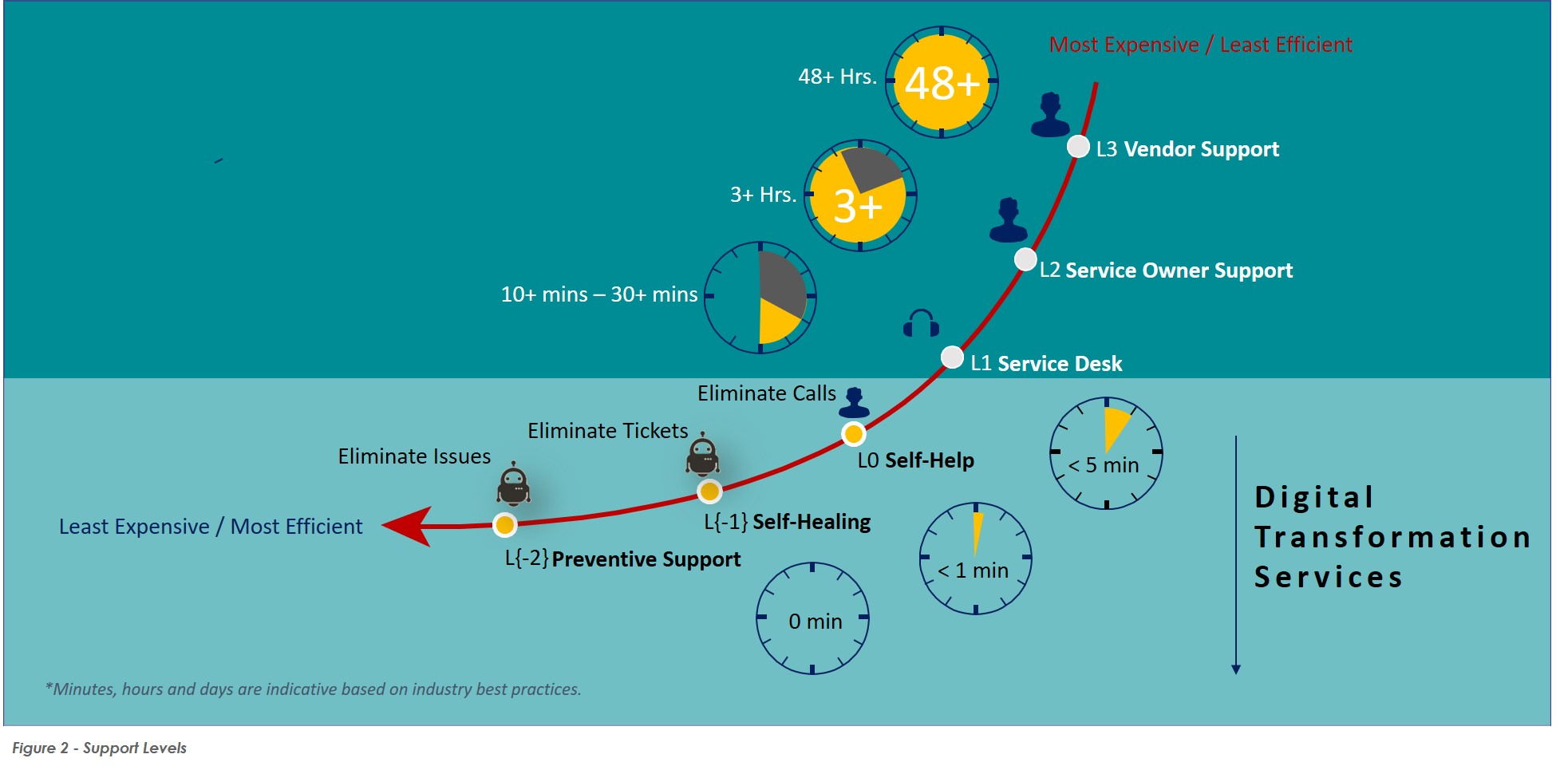
This has been a tried and tested model for over 20 years. Other than the advancement of self-healing and preventative support (more on this in a separate article), little has materially changed.
However, do you get that sinking feeling when your Service Desk Advisor says, ‘we need someone else to have a look at this, they will be in touch soon, here’s your ticket number’? When you hear from them a few days later, you end up explaining the situation all over again (while trying to convince them that you are more than just a ticket number).
Is there another way?
The concept of ticket ‘Swarming’ is not new. Swarming has had many names and incarnations such as ‘Collaborative Resolution’ and ‘Fast Track Support’. The basic principle:
- To improve resolution/fulfilment times, Incidents and Service Requests are assigned to the ‘best’ resource first time, and this resource will own the ticket from start to finish, drawing on other resource as required.
In addition to the single owner concept, advocates of this approach suggest this improves skills development of the assigned owner, which in turn informs resolution/fulfilment of future Incidents and Service Requests, thereby continually improving service.

But does this ‘work’ in practice? First, we recommend assessing Swarming effectiveness separately for Service Requests and Incidents, as follows:
Service Requests:
Set up effectively, swarming is not required for Service Requests. If there are issues (e.g. delays) with Service Request fulfilment, effort would be more effectively invested in defining your Requestable Services, and auto-assigning to the correct fulfilment team together with supporting work instructions. See our ‘Defining Requestable Services’ article for guidance.
Incidents:
Swarming Incidents does add value when applied in appropriate circumstances. There are typically four scenarios when there are challenges with Incident resolution, and Swarming is beneficial in one of them:

Recommended approach:
- in the Service Portal, the user should be prompted to select the impacted IT Service and symptom. Note – A prerequisite to this is an effective IT Service Catalogue integrated into the ITSM tool.
- based on the selection, the Incident will be auto routed to the correct Resolver Group (the Service Desk is not always the most appropriate fist line team).
- the Resolver Group manager, or on rota lead, conducts a regular review (e.g. hourly, albeit frequency depends on anticipated volume), and:
- Simple / quick resolution Incidents – allocates to an appropriate assignee within their Group based on their availability and capability.
- Inappropriately assigned Incidents – discussion held with the manager of the more suitable Resolver Group. Incident reallocated to that Group. Steps a) and, if required, c), are then followed within that newly allocated Group (with steps taking to avoid a repeat of the incorrect Incident assignment).
- SWARMING Complex Incidents (new plus any simple Incidents that have been proven to be more complex) – the Resolver Group manager, or on rota lead, holds a regular (e.g. daily) review with experienced team members and level 3 team members (on a rota) to discuss likely solutions, agree ownership and agree who needs to be involved. Incident is assigned accordingly. Note – Major Incidents invoke this approach immediately.
The assignee owns the Incident from start to finish. Any further input required from others is restricted to re-reviews at the regular complex Incidents review meeting.Taking this approach helps to maintain the benefits of why the Level 1 to 3 model was introduced, while providing much needed ownership and focus for the more complex Incidents. In turn, not only are Incidents resolved sooner, but the customer is provided with a better experience… while hopefully convincing customers that contacting “Mr/Mrs Dependable” in IT is no longer the best course of action!.
If you want to find out more about our services click here.
Disclaimer – opinions expressed in the text belong solely to the author, and not necessarily to the author’s employer or organisation.
Author: Chris Good
Published: LinkedIn